TryHackMe - Web Fundamentals


Task 1 - Introduction and Objectives
Although this room is designed to introduce you to the basics of how the web works, the content only scratches the surface so we're going dig a bit deeper.
Task 2 - How do we load websites
When a device connects to a network, it receives an IP address. This includes your home router, smart home devices, and web servers. The most common type of IP address is an IPv4, which is a 32-bit address 192.168.21.55 and capable of representing about 4.3 billion unique addresses. That was more than sufficient when it was created but these days that's simply not enough to meet the growing demands of the internet. Therefore, a newer 128-bit version called IPv6 was created that looks like 2001:0db8:85a3:0000:0000:8a2e:0370:7334 and allows for 340 trillion addresses.
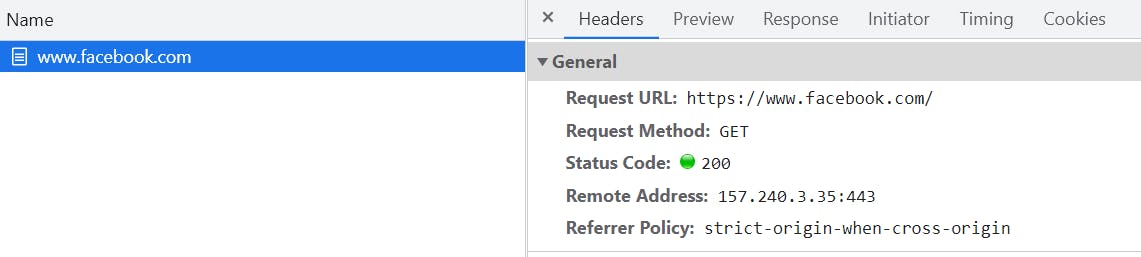
IPv4 addresses are hard enough to remember and IPv6 is nearly impossible for most people which is where the Domain Name System (DNS) comes in. Think of DNS as a phone directory that returns a phone number when provided with a name. When you type a domain name like google.com and press enter, the browser will first look up the IP address for google.com. Next, it will go to 74.125.142.101 and essentially say, "Hey, 74.125.142.101, please give me Google.com." The server will look for the requested resources and send them back. It will always include a status code when it responds saying it found the resource or maybe it couldn't find what you were looking for. The way it indicates this response is with a numerical code like 200 for success or 404 for not found or 500 if there was an error on the server. In this screenshot from the Chrome developer tools you can see the Requested URL, Requested Method, and Status Code:
Now that we understand at a high level how DNS works and how HTTP Requests are made, let's look at how the request is made in more detail. After you press Enter and the system looks up the IP address using DNS, the browser will establish a TCP connection to the server and then the browser will issue an HTTP request over that TCP/IP connection. By default, it will try to establish a connection on port 80 for standard HTTP or on port 443 for HTTPS which is the secure encrypted version. (It's worth mentioning that HTTP itself isn't secure or insecure, the request is essentially the same and HTTPS is simply telling the system it wants to use a secure TCP connection to send the requests rather than an insecure connection). If the connection is successful, it will make a request that includes the resource you're looking for and the request method. In HTTP there are 9 different request types but the two most common are GET and POST. A GET request is just what it sounds like, you are trying to retrieve resources from the server. With the POST request, you are trying to send data to the server such as a username and password.
Historically, most websites used standard HTTP and listened on port 80 for incoming requests. Typically, you only saw HTTPS on websites where you had lots of personal information like banks, online stores and other areas where you might be sending/receiving personal private information. Today, the majority of websites use HTTPS and that's primarily because search engines like Google have started to penalize websites that don't use HTTPS. If you try to visit a standard HTTP version of a website it will usually just redirect you to the HTTPS version.
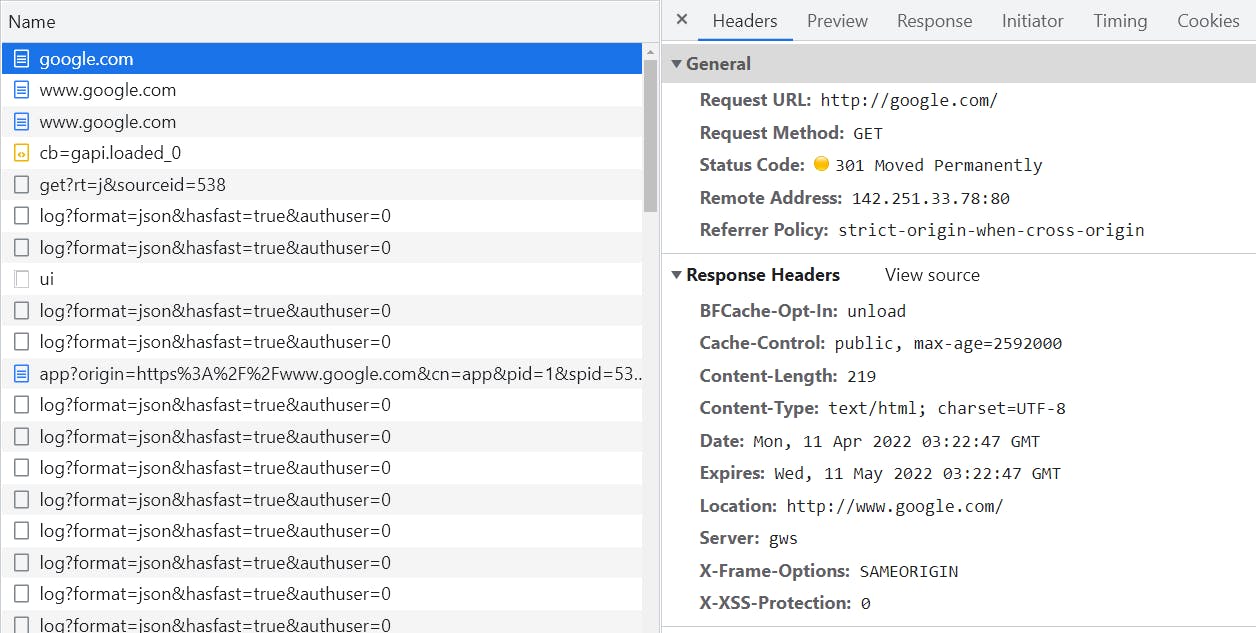
In the following screenshots, you can see this entire process at play. I opened a new tab, pressed F12 to open the developer tools, clicked the network tab, and then in the URL bar typed google.com. The first request goes to http://google.com on port 80. The server responds with a 301 Status Code indicating it has permanently moved to http://www.google.com. You can see this under the response headers section using the location header. Notice, that this location is also insecure and uses HTTP, not HTTPS.
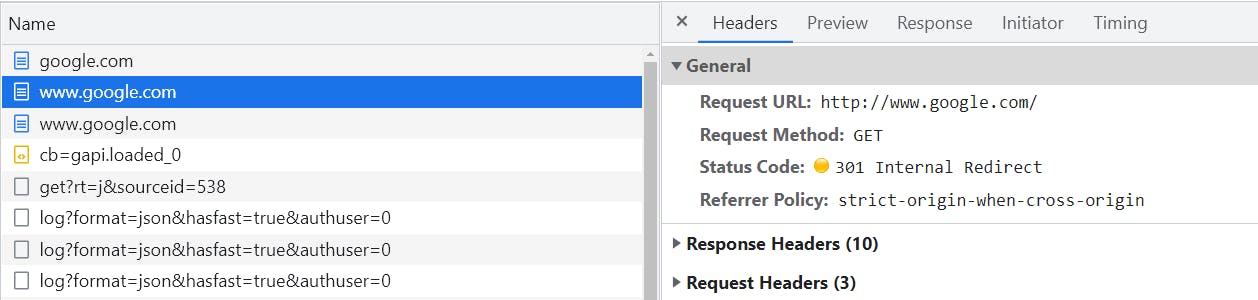
Next, it tries to go to the new location http://www.google.com but this time the 301 redirect is an "Internal Redirect". That's a special type of redirect where the browser intercepts your request and stops you from even trying to visit http://www.google.com because it's insecure and instead tries to establish a secure connection on port 443 before requesting www.google.com. This interception happens because of an HST Preload list which will be discussed in a later post but it's essentially a list embedded into the browser of websites that have said non-secure versions of their website should never be used under any circumstances.
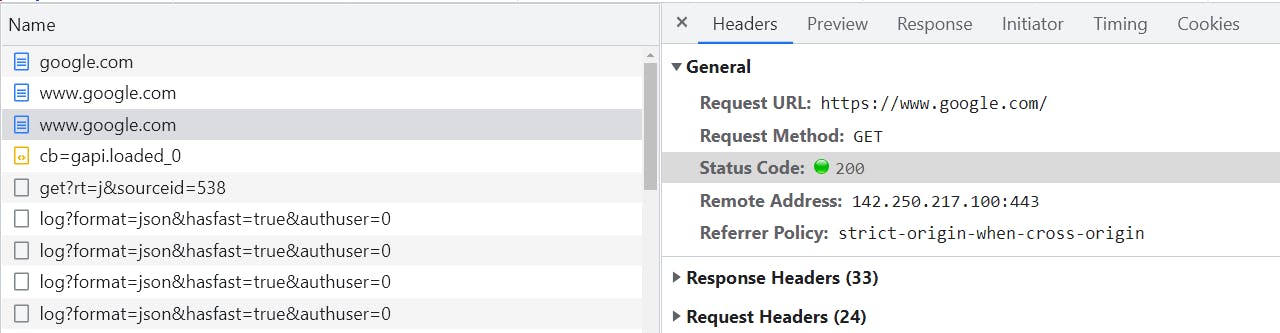
Finally, the browser attempts to request the website over the secure connection and is successful. The server responds with a 200 status indicating it was successful in finding the requested resource. Just to summarize, the browser looks up the IP address for google.com, establishes an insecure connection to 74.125.142.101, requests google.com but is redirected to www.google.com. When the browser attempts to request www.google.com, it's intercepted by the browser and this time a secure connection is established with 74.125.142.101 on port 443. Finally, it requests www.google.com over the secured connection and is successful.
Let's talk about why this is dangerous and what it means practically. To illustrate the vulnerability, consider a scenario where a person with malicious intent goes to a public area with a WiFi hotspot they control. They could name it something like "Free Guest Wi-Fi" and just wait for someone to connect. If that person tries to visit google.com the attacker could intercept it because it's insecure. The hacker could then present a fake version of Google's website and wait for someone to try logging in at which point they would have their username and password. This is a Man In The Middle (MITM) attack because the attacker is sitting between the person and the website they want to reach.
Let's get back to talking about requests. In most cases you aren't actually typing out the requests, instead, you probably start on one website such as google.com/news and then as you click on links the browser will handle everything we discussed previously for you. As it parses the new page, it automatically loads all the necessary resources like images, JavaScript files, and CSS files. Finally, it will put it all together in a process called rendering to show you a completed web page. It's not uncommon for a webpage these days to have dozens of resources like images and ads. JavaScript is used extensively these days to do everything from presenting ads to making the website interactive and CSS is used to make websites look fancy.
Q: What request verb is used to retrieve page content?
A: GET
Q: What port do web servers normally listen on?
A:80
Q: What's responsible for making websites look fancy? A: CSS
Task 3 - More HTTP - Verbs and request formats
Next, let's dive deeper into HTTP Requests, Methods and Responses. You may hear people talk about the browser connecting to websites and making requests but this isn't entirely accurate. When the browser wants to establish a connection to a web server, it delegates the task to the operating system's networking stack. The networking stack consists of protocols, drivers, and software used by the operating system to communicate over a network. The browser requests that the operating system establish a TCP connection to the server. This connection is like a tunnel between your machine and the server through which the browser can send requests using HTTP. These HTTP requests are actually quite simple and use plain text. To make this clear let's do this from the command line so we can see both steps independently. First, we can use this command to establish a Secure TCP connection to the server on port 443
$> openssl s_client -connect 242.12.24.45:443
...
---
It will display a bunch of data on the screen about the certificate and the connection (which I've omitted) and then at the end, you will have --- that indicates the connection is now established and waiting for you to send data. That's it, we now have a TCP connection to the server and can begin making HTTP requests. The key point I want to illustrate is the connection is separate from the HTTP Requests. To make the request you simply type something like this:
---
GET /login.html HTTP/1.1
Host: mysite.com
That's all we need to make an HTTP Request for the login page of mysite.com. We start by specifying the type of request which is a GET request, then the relative path of the resource which in this case is /login.html followed by the HTTP version HTTP/1.1. Hit return once to go to the next line and start the header section which is where the client and server can send all kinds of additional information to each other. In this case, we specify the host with Host: example.com. Finally, hit return twice and it will return all the data just as the browser does. If you leave out the Host it will just try with the IP address which may or may not work. If there are multiple domains hosted on the same server, it won't know which website /login.html belongs to and will try to default site.
To expand on this a bit further, it's not uncommon to have multiple websites on the same physical server and each website will have its own directory where all of its resources reside. For example, a server could host example.com, abc.com, and sentinel.org and could therefore have a directory setup like this:
/var/www/example.com/public/login.html
/var/www/abc.com/public/login.html
/var/www/sentinel.org/public/login.html
A configuration file would tell the server to look for all of example.com's files inside the directory /var/www/example.com/public/. When we include the host example.com, the server looks up the location of the files and tries to find login.html
The reason for having Request Methods is to allow the client such as a browser to tell the server what actions it would like to take on the requested resource (URL). Despite having all these methods available to us, many websites and applications have historically just used GET to retrieve data and POST to send data. However, it's becoming more common to see these other methods like DELETE when working with or developing RESTful APIs where the application is exposing individual resources in a more granular way.
Here's an example from Stripe's API for working with the customer object:
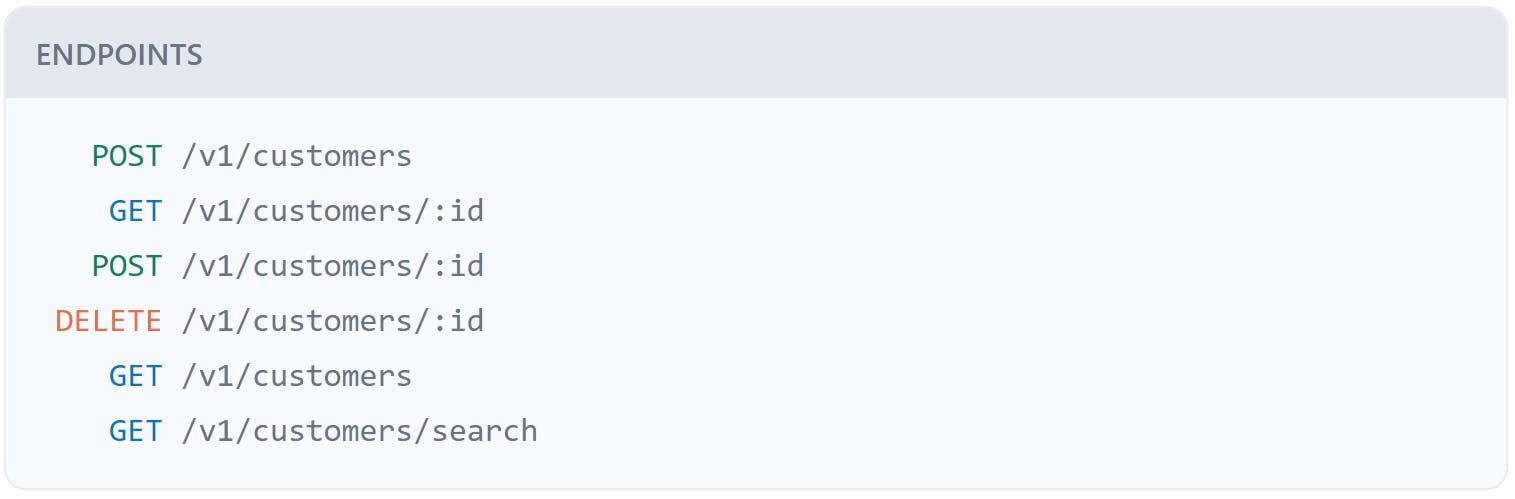
They show us a list of endpoints and HTTP Methods supported for each one. Notice that the endpoint /v1/customers/:id can support GET, POST, and DELETE. That's the same URL but three different actions depending on the Method you specify. The server will view each URL and HTTP Method combo as a unique request and can handle them differently.
Let's summarize everything we've covered so far in this section. The browser will ask the operating system to establish a connection to the server and then send HTTP requests over that connection. The request will specify what action it wants to take like GET, POST, or DELETE as well as the resource/URL name and the HOST since there can be multiple hosts on the same server. It will also likely include lots of other headers like this:
GET /main.js HTTP/1.1
Host: 192.168.170.129:8081
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36
Accept: */*
Referer: http://192.168.170.129:8081/
Accept-Encoding: gzip, deflate
Accept-Language: en-GB,en-US;q=0.9,en;q=0.8
Although I won't demonstrate it here, a POST request is very similar but you would have a body section after everything you see above. This body section would contain all the information you're sending to the server. The form field names and the input to those fields become key/value pairs. For example, you might have a body with something like username=myusername&password=mypassword. For GET requests you can send a body but you shouldn't and servers will almost certainly ignore the body in an HTTP GET request. After the request is made, the server will respond using the same HTTP protocol so it will look similar except it's responding to a request. Take a look at this response:
HTTP/1.1 200 OK
Server: nginx/1.10.3 (Ubuntu)
Date: Fri, 22 Apr 2022 23:22:37 GMT
Content-Type: text/html
Last-Modified: Sun, 01 Apr 2018 21:32:02 GMT
Transfer-Encoding: chunked
Connection: keep-alive
Content-Encoding: gzip
Notice the response starts by telling us it's using the HTTP/1.1 protocol and then it gives us a status code of 200 OK. As shown earlier this could also be something like 301 for a redirect or 404 Not Found if it couldn't find the resource. These HTTP response codes are split into categories for different types of errors. Here's a list:
100-199: Information 200-299: Successes (200 OK is the "normal" response for a GET) 300-399: Redirects (the information you want is elsewhere) 400-499: Client errors (the error is from the client request) 500-599: Server errors (The server tried, but something went wrong on their side)
These errors can be very useful in some cases and intentionally causing erros can be beneficial when trying ot hack into a website. For example, if you type a really long string of text into a search box it might cause a 500 error on the server which can result in displaying a stack trace on the website which then reveals information about the server.
Q: What verb would be used for a login?
A: POST
Q: What verb would be used to see your bank balance once you're logged in?
A: GET
Q: Does the body of a GET request matter? Yea/Nay
A: Nay
Q: What's the status code for "I'm a teapot"? A: 418 (Yeah, go read about this one but it's a real but useless error.)
Q: What status code will you get if you need to authenticate to access some content, and you're unauthenticated? A: 401